
When it comes to large language model-powered tools, there are generally two broad categories of users. On one side are those who treat AI as a powerful but sometimes faulty service that needs careful human oversight and review to detect reasoning or factual flaws in responses. On the other side are those who routinely outsource their critical thinking to what they see as an all-knowing machine.
Recent research goes a long way to forming a new psychological framework for that second group, which regularly engages in "cognitive surrender" to AI's seemingly authoritative answers. That research also provides some experimental examination of when and why people are willing to outsource their critical thinking to AI, and how factors like time pressure and external incentives can affect that decision.
Just ask the answer machine
In "Thinking—Fast, Slow, and Artificial: How AI is Reshaping Human Reasoning and the Rise of Cognitive Surrender," researchers from the University of Pennsylvania sought to build on existing scholarship that outlines two broad categories of decision-making: one shaped by "fast, intuitive, and affective processing" (System 1); and one shaped by "slow, deliberative, and analytical reasoning" (System 2). The onset of AI systems, the researchers argue, has created a new, third category of "artificial cognition" in which decisions are driven by "external, automated, data-driven reasoning originating from algorithmic systems rather than the human mind."
In the past, people have often used tools from calculators to GPS systems for a kind of task-specific "cognitive offloading," strategically delegating some jobs to reliable automated algorithms while using their own internal reasoning to oversee and evaluate the results. But the researchers argue that AI systems have given rise to a categorically different form of "cognitive surrender" in which users provide "minimal internal engagement" and accept an AI's reasoning wholesale without oversight or verification. This "uncritical abdication of reasoning itself" is particularly common when an LLM's output is "delivered fluently, confidently, or with minimal friction," they point out.
To measure the prevalence and effect of this kind of cognitive surrender to AI, the researchers performed a number of studies based on Cognitive Reflection Tests. These tests are designed to elicit incorrect answers from participants that default to "intuitive" (System 1) thought processes, but to be relatively simple to answer for those who use more "deliberative" (System 2) thought processes.
 Test subjects who consulted AI were overwhelmingly willing to accept its answers without scrutiny, whether correct or not.
Credit:
Shaw and Nave
Test subjects who consulted AI were overwhelmingly willing to accept its answers without scrutiny, whether correct or not.
Credit:
Shaw and Nave
For their experiments, the researchers provided participants with optional access to an LLM chatbot that had been modified to randomly provide inaccurate answers to the CRT questions about half the time (and accurate answers the other half). The researchers hypothesized that users who frequently consulted the chatbot would let those incorrect answers "override intuitive and deliberative processes," hurting their overall performance and highlighting the dangers of cognitive surrender.
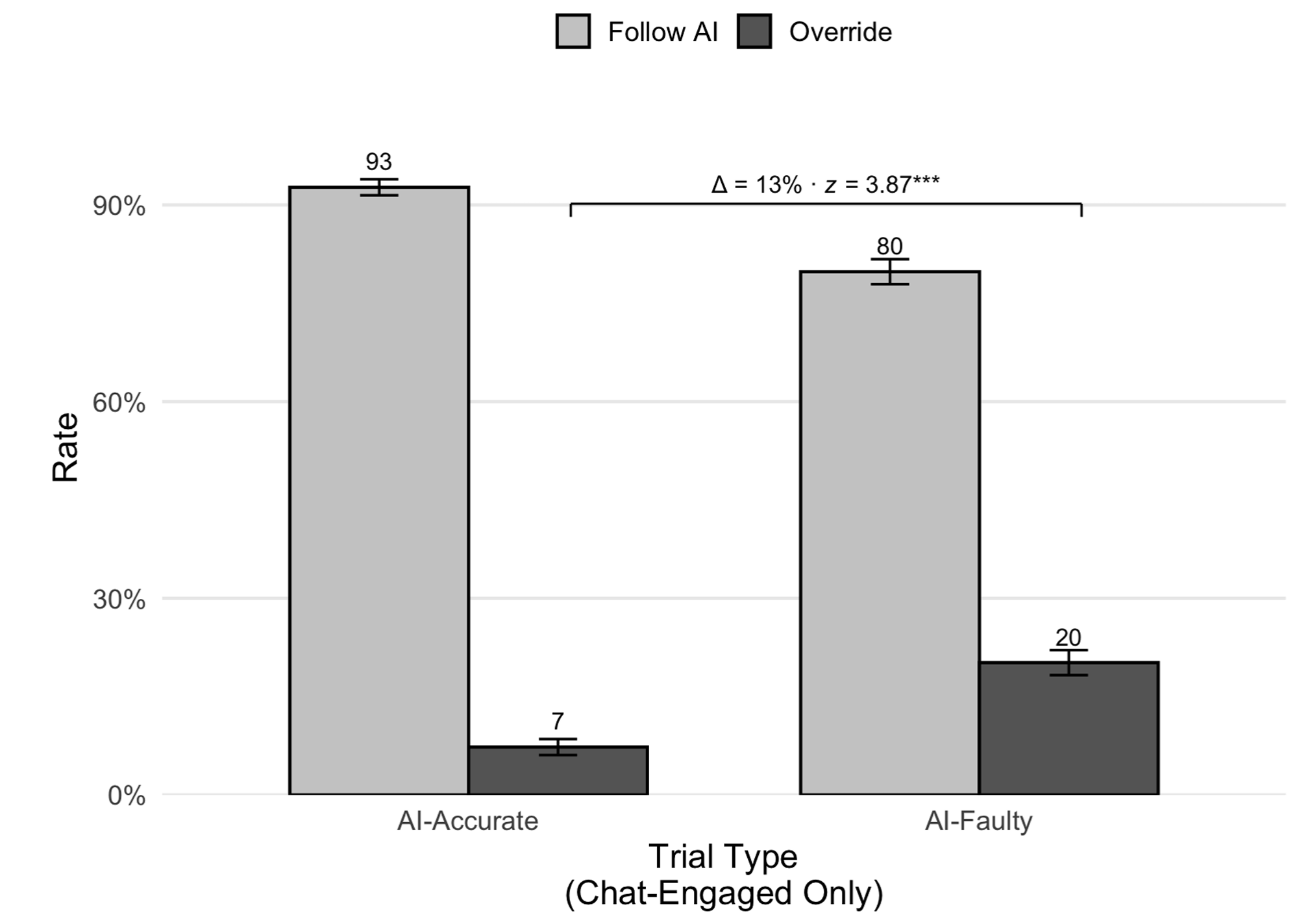
In one study, an experimental group with access to this modified AI consulted it for help with about 50 percent of the presented CRT problems. When the AI was accurate, those AI users accepted its reasoning about 93 percent of the time. When the AI was randomly "faulty," though, those users still accepted the AI reasoning a lower (but still high) 80 percent of the time, showing that the mere presence of the AI frequently "displaced internal reasoning," according to the researchers.
Unsurprisingly, the AI-using experimental group did much better than the "brain-only" control group when the AI provided accurate answers, and much worse than the control when the AI was inaccurate. Significantly, though, the group that used AI scored 11.7 percent higher on a measure of their own confidence in their answers, even though the LLM provided wrong answers half the time.
In another study, adding incentives (in the form of small payments) and immediate feedback for correct answers increased the likelihood that participants successfully overruled the faulty AI by 19 percentage points relative to the baseline, showing that salient consequences can encourage AI users to spend extra time verifying responses. But adding time pressures in the form of a 30-second timer decreased that tendency to correct the faulty AI by 12 percentage points, suggesting to the researchers that "when decision time is scarce, the internal monitor detecting conflict and recruiting deliberation is less likely to trigger."
"Lowering the threshold for scrutiny"
Overall, across 1,372 participants and over 9,500 individual trials, the researchers found subjects were willing to accept faulty AI reasoning a whopping 73.2 percent of the time, while only overruling it 19.7 percent of the time. The researchers say this "demonstrate[s] that people readily incorporate AI-generated outputs into their decision-making processes, often with minimal friction or skepticism." In general, "fluent, confident outputs [are treated] as epistemically authoritative, lowering the threshold for scrutiny and attenuating the meta-cognitive signals that would ordinarily route a response to deliberation," they write.
 Subjects with high trust in AI were more likely to be misled by faulty responses, while those with high "Fluid IQ" were less likely to be misled by the AI.
Credit:
Shaw and Nave
Subjects with high trust in AI were more likely to be misled by faulty responses, while those with high "Fluid IQ" were less likely to be misled by the AI.
Credit:
Shaw and Nave
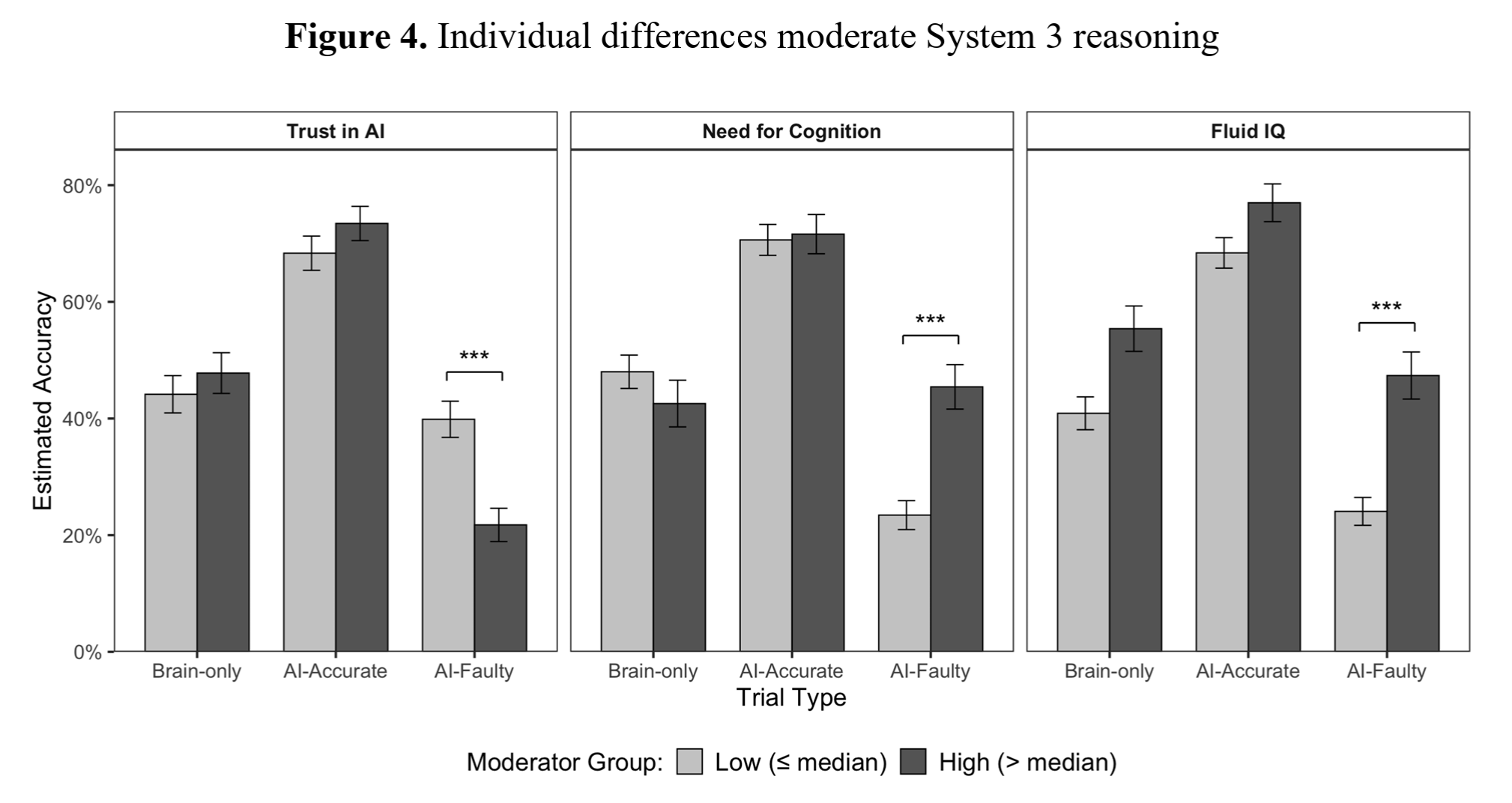
These kinds of effects weren't uniform across all test subjects, though. Those who scored highly on separate measures of so-called fluid IQ were less likely to rely on the AI for help and were more likely to overrule a faulty AI when it was consulted. Those predisposed to see AI as authoritative in a survey, on the other hand, were much more likely to be led astray by faulty AI-provided answers.
Despite the results, though, the researchers point out that "cognitive surrender is not inherently irrational." While relying on an LLM that's wrong half the time (as in these experiments) has obvious downsides, a "statistically superior system" could plausibly give better-than-human results in domains such as "probabilistic settings, risk assessment, or extensive data," the researchers suggest.
"As reliance increases, performance tracks AI quality," the researchers write, "rising when accurate and falling when faulty, illustrating the promises of superintelligence and exposing a structural vulnerability of cognitive surrender."
In other words, letting an AI do your reasoning means your reasoning is only ever going to be as good as that AI system. As always, let the prompter beware.


